CDC Connectors for Apache Flink¶
CDC Connectors for Apache Flink® is a set of source connectors for Apache Flink®, ingesting changes from different databases using change data capture (CDC). The CDC Connectors for Apache Flink® integrate Debezium as the engine to capture data changes. So it can fully leverage the ability of Debezium. See more about what is Debezium.
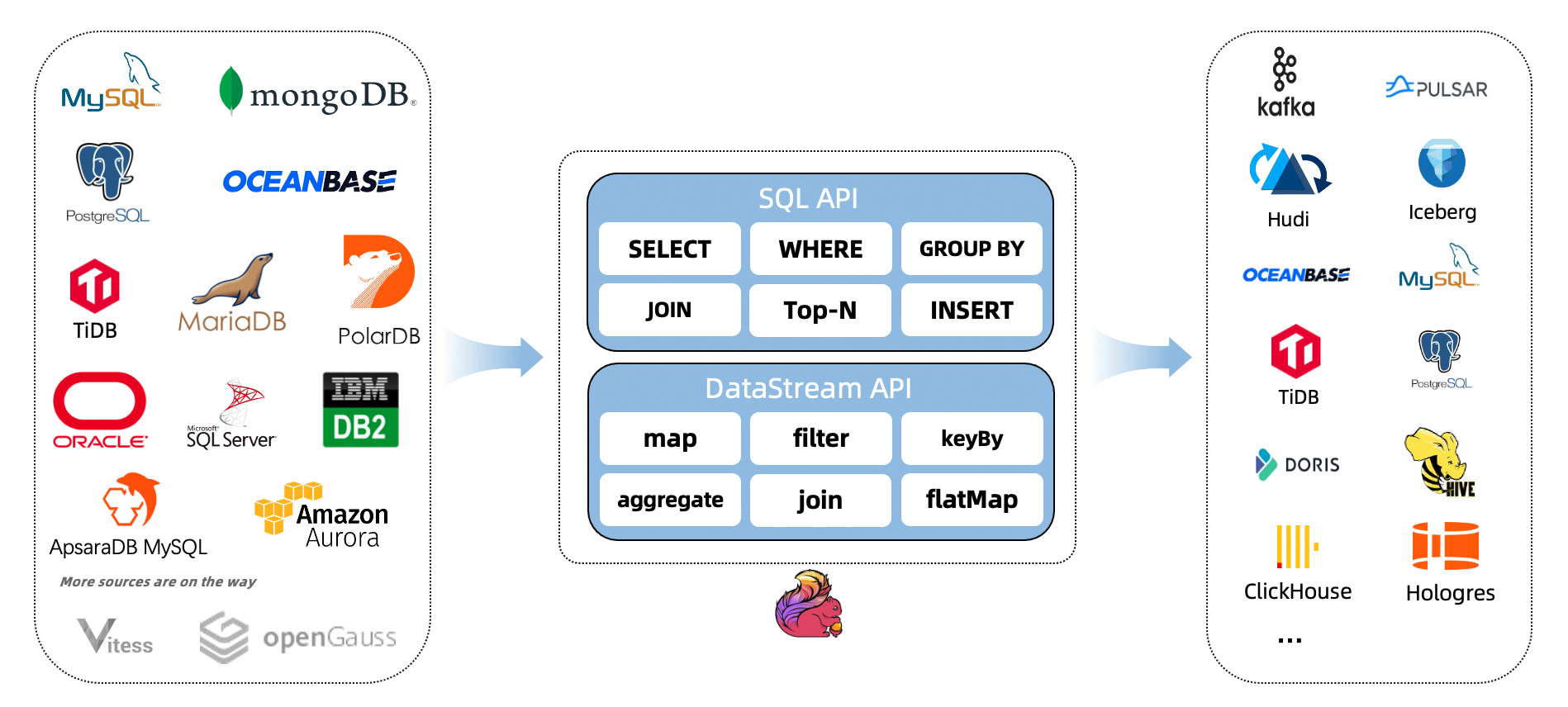
Supported Connectors¶
Connector |
Database |
Driver |
|---|---|---|
MongoDB Driver: 4.3.4 |
||
JDBC Driver: 8.0.28 |
||
OceanBase Driver: 2.4.x |
||
Oracle Driver: 19.3.0.0 |
||
JDBC Driver: 42.5.1 |
||
JDBC Driver: 9.4.1.jre8 |
||
JDBC Driver: 8.0.27 |
||
Db2 Driver: 11.5.0.0 |
||
MySql JDBC Driver: 8.0.26 |
Supported Flink Versions¶
The following table shows the version mapping between Flink® CDC Connectors and Flink®:
Flink® CDC Version |
Flink® Version |
|---|---|
1.0.0 |
1.11.* |
1.1.0 |
1.11.* |
1.2.0 |
1.12.* |
1.3.0 |
1.12.* |
1.4.0 |
1.13.* |
2.0.* |
1.13.* |
2.1.* |
1.13.* |
2.2.* |
1.13.*, 1.14.* |
2.3.* |
1.13.*, 1.14.*, 1.15.*, 1.16.* |
2.4.* |
1.13.*, 1.14.*, 1.15.*, 1.16.*, 1.17.* |
3.0.* |
1.14.*, 1.15.*, 1.16.*, 1.17.*, 1.18.* |
Features¶
Supports reading database snapshot and continues to read binlogs with exactly-once processing even failures happen.
CDC connectors for DataStream API, users can consume changes on multiple databases and tables in a single job without Debezium and Kafka deployed.
CDC connectors for Table/SQL API, users can use SQL DDL to create a CDC source to monitor changes on a single table.
The following table shows the current features of the connector:
Connector |
No-lock Read |
Parallel Read |
Exactly-once Read |
Incremental Snapshot Read |
|---|---|---|---|---|
✅ |
✅ |
✅ |
✅ |
|
✅ |
✅ |
✅ |
✅ |
|
✅ |
✅ |
✅ |
✅ |
|
✅ |
✅ |
✅ |
✅ |
|
✅ |
✅ |
✅ |
✅ |
|
❌ |
❌ |
❌ |
❌ |
|
✅ |
❌ |
✅ |
❌ |
|
❌ |
❌ |
✅ |
❌ |
|
✅ |
❌ |
✅ |
❌ |
Usage for Table/SQL API¶
We need several steps to setup a Flink cluster with the provided connector.
Setup a Flink cluster with version 1.12+ and Java 8+ installed.
Download the connector SQL jars from the Downloads page (or build yourself).
Put the downloaded jars under
FLINK_HOME/lib/.Restart the Flink cluster.
The example shows how to create a MySQL CDC source in Flink SQL Client and execute queries on it.
-- creates a mysql cdc table source
CREATE TABLE mysql_binlog (
id INT NOT NULL,
name STRING,
description STRING,
weight DECIMAL(10,3),
PRIMARY KEY(id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'flinkuser',
'password' = 'flinkpw',
'database-name' = 'inventory',
'table-name' = 'products'
);
-- read snapshot and binlog data from mysql, and do some transformation, and show on the client
SELECT id, UPPER(name), description, weight FROM mysql_binlog;
Usage for DataStream API¶
Include following Maven dependency (available through Maven Central):
<dependency>
<groupId>com.ververica</groupId>
<!-- add the dependency matching your database -->
<artifactId>flink-connector-mysql-cdc</artifactId>
<!-- The dependency is available only for stable releases, SNAPSHOT dependencies need to be built based on master or release- branches by yourself. -->
<version>3.0-SNAPSHOT</version>
</dependency>
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
public class MySqlBinlogSourceExample {
public static void main(String[] args) throws Exception {
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("yourHostname")
.port(yourPort)
.databaseList("yourDatabaseName") // set captured database
.tableList("yourDatabaseName.yourTableName") // set captured table
.username("yourUsername")
.password("yourPassword")
.deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// enable checkpoint
env.enableCheckpointing(3000);
env
.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")
// set 4 parallel source tasks
.setParallelism(4)
.print().setParallelism(1); // use parallelism 1 for sink to keep message ordering
env.execute("Print MySQL Snapshot + Binlog");
}
}
Deserialization¶
The following JSON data show the change event in JSON format.
{
"before": {
"id": 111,
"name": "scooter",
"description": "Big 2-wheel scooter",
"weight": 5.18
},
"after": {
"id": 111,
"name": "scooter",
"description": "Big 2-wheel scooter",
"weight": 5.15
},
"source": {...},
"op": "u", // the operation type, "u" means this this is an update event
"ts_ms": 1589362330904, // the time at which the connector processed the event
"transaction": null
}
Note: Please refer Debezium documentation to know the meaning of each field.
In some cases, users can use the JsonDebeziumDeserializationSchema(true) Constructor to enabled include schema in the message. Then the Debezium JSON message may look like this:
{
"schema": {
"type": "struct",
"fields": [
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
{
"type": "string",
"optional": false,
"default": "flink",
"field": "name"
},
{
"type": "string",
"optional": true,
"field": "description"
},
{
"type": "double",
"optional": true,
"field": "weight"
}
],
"optional": true,
"name": "mysql_binlog_source.inventory_1pzxhca.products.Value",
"field": "before"
},
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
{
"type": "string",
"optional": false,
"default": "flink",
"field": "name"
},
{
"type": "string",
"optional": true,
"field": "description"
},
{
"type": "double",
"optional": true,
"field": "weight"
}
],
"optional": true,
"name": "mysql_binlog_source.inventory_1pzxhca.products.Value",
"field": "after"
},
{
"type": "struct",
"fields": {...},
"optional": false,
"name": "io.debezium.connector.mysql.Source",
"field": "source"
},
{
"type": "string",
"optional": false,
"field": "op"
},
{
"type": "int64",
"optional": true,
"field": "ts_ms"
}
],
"optional": false,
"name": "mysql_binlog_source.inventory_1pzxhca.products.Envelope"
},
"payload": {
"before": {
"id": 111,
"name": "scooter",
"description": "Big 2-wheel scooter",
"weight": 5.18
},
"after": {
"id": 111,
"name": "scooter",
"description": "Big 2-wheel scooter",
"weight": 5.15
},
"source": {...},
"op": "u", // the operation type, "u" means this this is an update event
"ts_ms": 1589362330904, // the time at which the connector processed the event
"transaction": null
}
}
Usually, it is recommended to exclude schema because schema fields makes the messages very verbose which reduces parsing performance.
The JsonDebeziumDeserializationSchema can also accept custom configuration of JsonConverter, for example if you want to obtain numeric output for decimal data,
you can construct JsonDebeziumDeserializationSchema as following:
Map<String, Object> customConverterConfigs = new HashMap<>();
customConverterConfigs.put(JsonConverterConfig.DECIMAL_FORMAT_CONFIG, "numeric");
JsonDebeziumDeserializationSchema schema =
new JsonDebeziumDeserializationSchema(true, customConverterConfigs);
Building from source¶
Prerequisites:
git
Maven
At least Java 8
git clone https://github.com/ververica/flink-cdc-connectors.git
cd flink-cdc-connectors
mvn clean install -DskipTests
The dependencies are now available in your local .m2 repository.
Code Contribute¶
Left comment under the issue that you want to take
Fork Flink CDC project to your GitHub repositories

Clone and compile your Flink CDC project
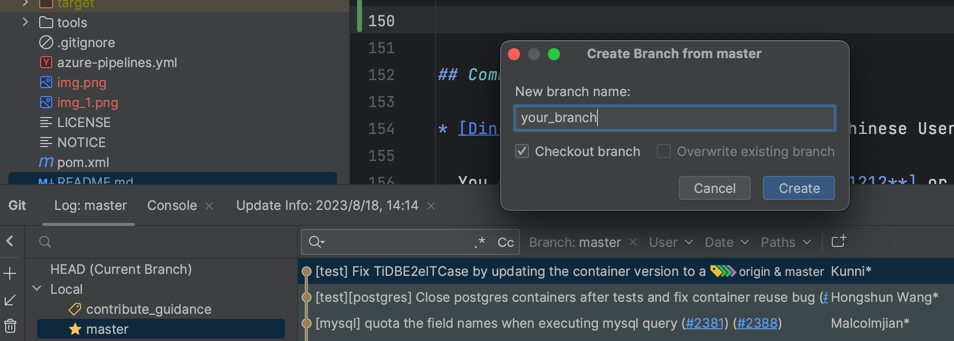
git clone https://github.com/your_name/flink-cdc-connectors.git cd flink-cdc-connectors mvn clean install -DskipTestsCheck to a new branch and start your work
git checkout -b my_feature -- develop and commit
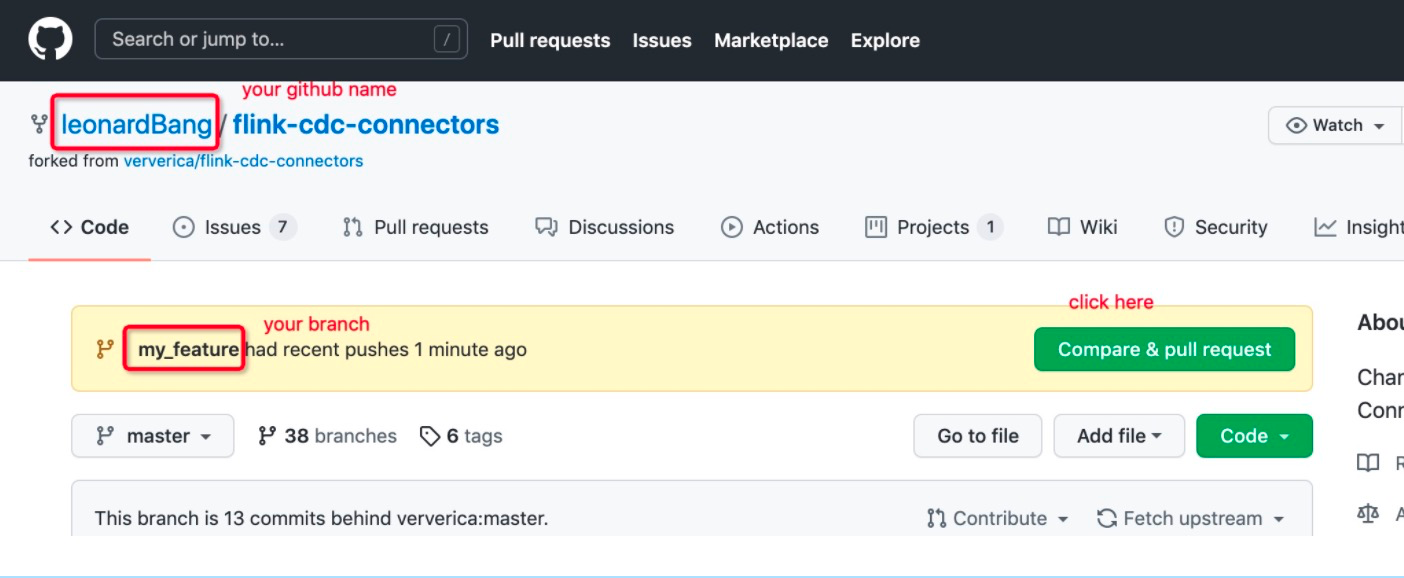
Push your branch to your github
git push origin my_feature
Open a PR to https://github.com/ververica/flink-cdc-connectors
Code Style¶
Code Formatting¶
You need to install the google-java-format plugin. Spotless together with google-java-format is used to format the codes.
It is recommended to automatically format your code by applying the following settings:
Go to “Settings” → “Other Settings” → “google-java-format Settings”.
Tick the checkbox to enable the plugin.
Change the code style to “Android Open Source Project (AOSP) style”.
Go to “Settings” → “Tools” → “Actions on Save”.
Under “Formatting Actions”, select “Optimize imports” and “Reformat file”.
From the “All file types list” next to “Reformat code”, select “Java”.
For earlier IntelliJ IDEA versions, the step 4 to 7 will be changed as follows.
4.Go to “Settings” → “Other Settings” → “Save Actions”.
5.Under “General”, enable your preferred settings for when to format the code, e.g. “Activate save actions on save”.
6.Under “Formatting Actions”, select “Optimize imports” and “Reformat file”.
7.Under “File Path Inclusions”, add an entry for
.*\.javato avoid formatting other file types. Then the whole project could be formatted by commandmvn spotless:apply.
Checkstyle¶
Checkstyle is used to enforce static coding guidelines.
Go to “Settings” → “Tools” → “Checkstyle”.
Set “Scan Scope” to “Only Java sources (including tests)”.
For “Checkstyle Version” select “8.14”.
Under “Configuration File” click the “+” icon to add a new configuration.
Set “Description” to “Flink cdc”.
Select “Use a local Checkstyle file” and link it to the file
tools/maven/checkstyle.xmlwhich is located within your cloned repository.Select “Store relative to project location” and click “Next”.
Configure the property
checkstyle.suppressions.filewith the valuesuppressions.xmland click “Next”.Click “Finish”.
Select “Flink cdc” as the only active configuration file and click “Apply”.
You can now import the Checkstyle configuration for the Java code formatter.
Go to “Settings” → “Editor” → “Code Style” → “Java”.
Click the gear icon next to “Scheme” and select “Import Scheme” → “Checkstyle Configuration”.
Navigate to and select
tools/maven/checkstyle.xmllocated within your cloned repository.
Then you could click “View” → “Tool Windows” → “Checkstyle” and find the “Check Module” button in the opened tool window to validate checkstyle. Or you can use the command mvn clean compile checkstyle:checkstyle to validate.
Documentation Contribute¶
Flink cdc documentations locates at docs/content.
The contribution step is the same as the code contribution. We use markdown as the source code of the document.
License¶
The code in this repository is licensed under the Apache Software License 2.